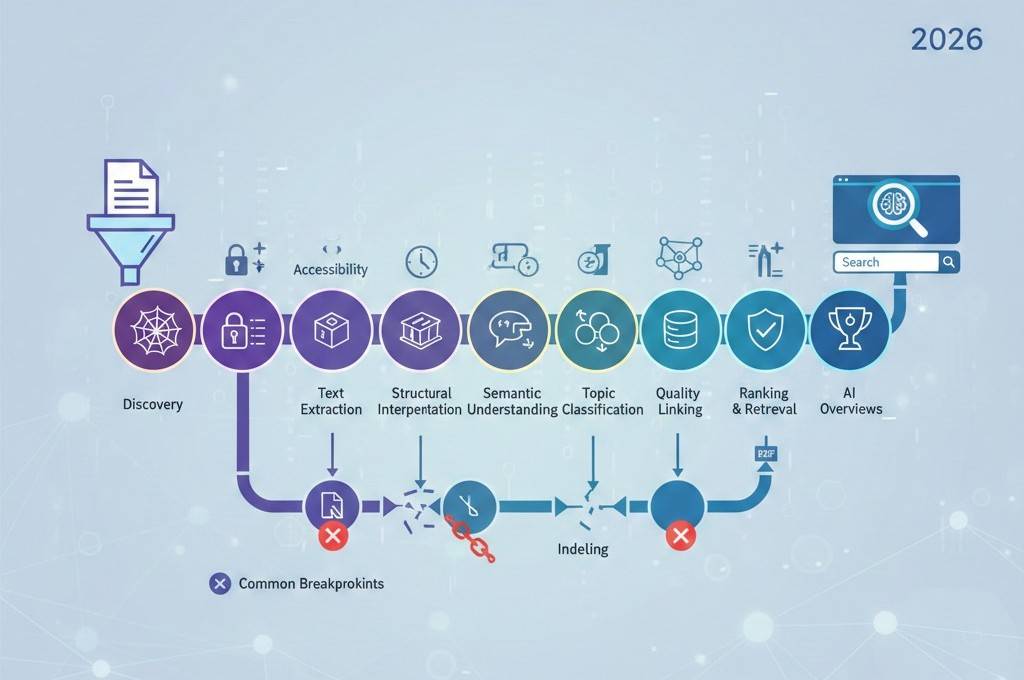
AI-dokumentindekseringslivssyklusen forklart fra opplasting til søkesynlighet
Hva skjer etter at et dokument er publisert
Å publisere et dokument gjør det ikke automatisk synlig i AI-drevet søk. I 2026 beveger dokumenter seg gjennom en strukturert livssyklus før de kan indekseres, forstås, oppsummeres og vises i søkeresultater.
Denne livssyklusen gjelder både for nettsider og PDF-er. Å forstå hvordan AI-systemer behandler dokumenter hjelper utgivere med å forbedre klarhet, tilgjengelighet og langsiktig synlighet.
Denne artikkelen forklarer hvert trinn i livssyklusen for AI-dokumentindeksering og hvordan dokumentkvaliteten påvirker resultatene ved hvert trinn.
Trinn 1: Dokumentoppdagelse
Livssyklusen begynner når AI-systemer oppdager et dokument.
Oppdagelsen skjer gjennom:
- Gjennomsøker offentlige nettadresser
- Intern kobling
- Eksterne referanser
- Brukertilgangsmønstre
Dokumenter som er enkle å få tilgang til og som er riktig koblet, oppdages raskere.
Publisering av standardiserte PDF-filer forbedrer tilgjengeligheten på tvers av plattformer.
Trinn 2: Filtilgjengelighet og teknisk beredskap
Før AI kan lese innhold, sjekker den teknisk tilgjengelighet.
Nøkkelfaktorer inkluderer:
- Filtilgjengelighet
- Last ytelse
- Formatkompatibilitet
- Feilfri gjengivelse
PDF-filer foretrekkes fordi de gjengis konsekvent.
Optimalisering av filstørrelse forbedrer tilgjengeligheten.
Mindre filer reduserer behandlingsfriksjonen.
Trinn 3: Tekstutvinning og analysering
Når den er tilgjengelig, trekker AI ut tekst og struktur.
For PDF-er inkluderer dette:
- Leser valgbar tekst
- Identifiser siderekkefølge
- Gjenkjenne overskrifter
- Skille lister og tabeller
PDF-filer som kun er bilde reduserer nøyaktigheten for utvinning.
Konvertering av bilder til PDF-filer hjelper å analysere.
Trinn 4: Strukturell tolkning
AI tolker deretter dokumentstrukturen.
Sterke signaler inkluderer:
- Tydelige titler
- Logiske overskrifter
- Konsekvent formatering
- Definerte seksjoner
Dårlig struktur bremser forståelsen og reduserer selvtilliten.
Mange dokumenter forbedrer strukturen under redigering.
Eksempel på redigering av arbeidsflyt:
- PDF til Word for foredling
- Word til PDF for endelig struktur
Trinn 5: Semantisk forståelse
Etter at struktur er gjenkjent, analyserer AI betydning.
Dette inkluderer:
- Identifisere hovedemner
- Forstå sammenhenger mellom seksjoner
- Å oppdage definisjoner og forklaringer
- Kartlegging av enheter og konsepter
Semantisk klarhet er viktigere enn gjentakelse av søkeord.
Trinn 6: Emneklassifisering og gruppering
AI tildeler dokumentet til emnekategorier.
Den sammenligner innhold med eksisterende dokumenter for å fastslå:
- Temarelevans
- Likhet med kjente kilder
- Plassering i emneklynger
Dokumenter som er tydelig på linje med en emneklynge får sterkere synlighet.
Publisering av relaterte dokumenter styrker konsekvent klassifiseringen.
Trinn 7: Oppsummering og kunnskapsutvinning
AI genererer interne sammendrag for å teste forståelsen.
Dokumenter av høy kvalitet:
- Oppsummer tydelig
- Ta vare på nøkkelpunkter
- Oppretthold logisk flyt
Dårlig oppsummering signaliserer svak struktur eller uklare meldinger.
Rene oppsummeringer forbedrer selvtilliten.
Trinn 8: Kvalitets- og tillitsevaluering
AI evaluerer tillit og pålitelighet ved hjelp av indirekte signaler.
Disse inkluderer:
- Konsistens på tvers av seksjoner
- Saklig tone
- Fravær av manipulasjon
- Teknisk kvalitet
Signaler av lav kvalitet bremser eller stopper fremdriften i livssyklusen.
Trinn 9: Kontekstuell kobling og relasjoner
AI evaluerer hvordan dokumentet forholder seg til andre.
Relaterte dokumenter som:
- Del terminologi
- Dekk tilknyttede underemner
- Oppretthold konsistent struktur
er knyttet sammen.
Slå sammen relaterte filer styrker konteksten.
Enhetlig kontekst forbedrer forståelsen.
Trinn 10: Indeksering og lagring
Når det er evaluert, blir dokumentet indeksert.
Indeksering inkluderer:
- Lagring av semantisk representasjon
- Tilknyttede enheter og emner
- Kobling med relatert innhold
Indekserte dokumenter blir kvalifisert for søkeresultater og AI-sammendrag.
Trinn 11: Rangering og henting
Når en bruker søker, henter AI dokumenter basert på:
- Relevans
- Autoritet
- Klarhet
- Kontekstmatch
Rangeringen er dynamisk og påvirket av pågående signaler.
Trinn 12: Inkludering i AI-oversikter
Bare et undersett av dokumenter påvirker AI-oversikter.
Dokumenter valgt vanligvis:
- Forklar emner tydelig
- Bruk nøytralt språk
- Unngå overdreven markedsføring
- Gi fullstendige svar
PDF-filer som oppfyller disse kriteriene er sterke kandidater.
Vanlige bruddpunkter i livssyklusen
Dokumenter mislykkes ofte ved:
- Tekstuttrekking på grunn av innhold som kun er bilde
- Strukturell forvirring
- Mangel på temafokus
- Tekniske ytelsesproblemer
Å fikse problemer i tidlig fase forbedrer nedstrøms synlighet.
Hvorfor standardisering forbedrer hele livssyklusen
Standardiserte PDF-filer støtter alle trinn.
Fordelene inkluderer:
- Enklere parsing
- Renere struktur
- Stabil semantikk
- Bedre oppsummeringer
Konvertering av proprietære formater som Pages forbedrer konsistensen.
Ekstern innsikt i indekseringssystemer
Ifølge Google Search Central , tydelig struktur og tilgjengelighet hjelper systemene med å forstå og indeksere innhold nøyaktig:
Denne veiledningen gjelder også for PDF-filer.
Konklusjon: Synlighet er en prosess, ikke et øyeblikk
AI-dokumentsynlighet er resultatet av en flertrinns livssyklus. Fra oppdagelse til oppsummering avhenger hvert trinn av klarhet, struktur og konsistens.
PDF-filer som er standardiserte, optimaliserte og fokuserte beveger seg jevnt gjennom denne livssyklusen og får sterkere langsiktig synlighet. Å forstå denne prosessen hjelper utgivere med å lage dokumenter som ikke bare er publisert, men også forstått. I AI-drevne søkemiljøer kommer suksess fra å støtte alle trinn i indekseringslivssyklusen.
Vanlige spørsmål
Hvor lang tid tar AI-indeksering
Det varierer basert på tilgjengelighet, struktur og kvalitet.
Går PDF-filer gjennom samme livssyklus som nettsider
Ja. Prinsippene er de samme.
Kan dokumenter indekseres på nytt
Ja. Oppdateringer utløser reevaluering.
Påvirker filformat indeksering
Ja. Standardiserte formater indekserer mer pålitelig.
Kan dårlig struktur blokkere indeksering
Ja. Strukturell forvirring kan stoppe fremgang tidlig.