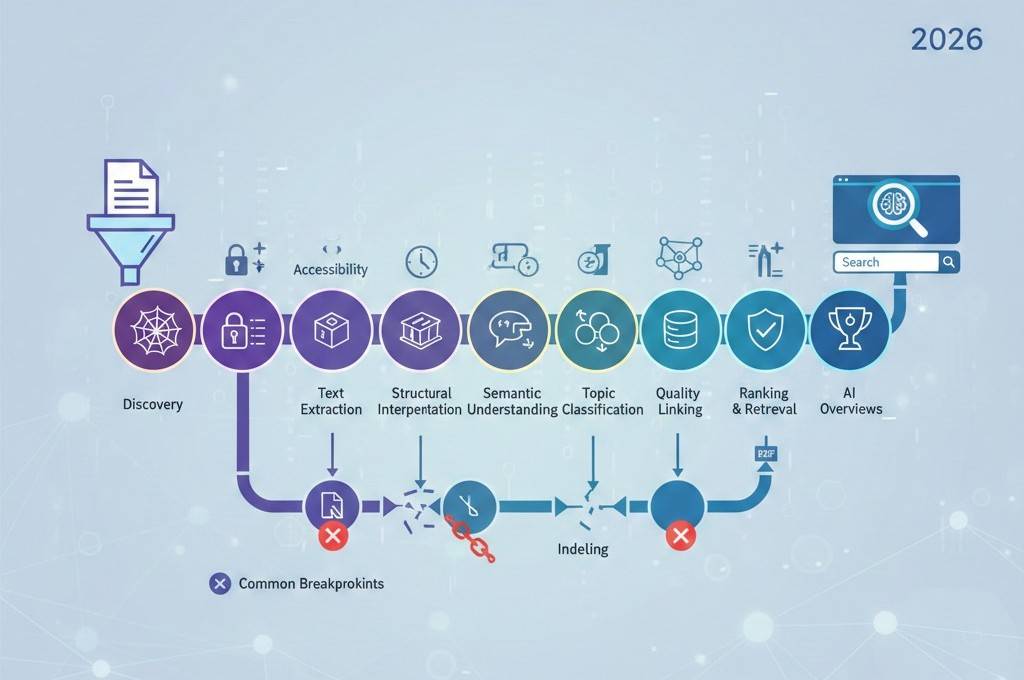
AI-dokumentindekseringslivscyklussen forklaret fra upload til søgesynlighed
Hvad sker der efter et dokument er offentliggjort
Udgivelse af et dokument gør det ikke automatisk synligt i AI-drevet søgning. I 2026 bevæger dokumenter sig gennem en struktureret livscyklus, før de kan indekseres, forstås, opsummeres og vises i søgeresultaterne.
Denne livscyklus gælder både for websider og PDF'er. At forstå, hvordan AI-systemer behandler dokumenter, hjælper udgivere med at forbedre klarhed, tilgængelighed og langsigtet synlighed.
Denne artikel forklarer hvert trin i AI-dokumentindekseringens livscyklus, og hvordan dokumentkvaliteten påvirker resultaterne ved hvert trin.
Fase 1: Dokumentopdagelse
Livscyklussen begynder, når AI-systemer opdager et dokument.
Opdagelsen sker gennem:
- Gennemgang af offentlige webadresser
- Intern linking
- Eksterne referencer
- Brugeradgangsmønstre
Dokumenter, der er nemme at få adgang til og korrekt linkede, opdages hurtigere.
Udgivelse af standardiserede PDF'er forbedrer tilgængeligheden på tværs af platforme.
Trin 2: Filtilgængelighed og teknisk beredskab
Før AI kan læse indhold, tjekker den teknisk tilgængelighed.
Nøglefaktorer omfatter:
- Filtilgængelighed
- Belastningsydelse
- Formatkompatibilitet
- Fejlfri gengivelse
PDF-filer foretrækkes, fordi de gengives konsekvent.
Optimering af filstørrelse forbedrer tilgængeligheden.
Mindre filer reducerer behandlingsfriktion.
Trin 3: Tekstudtrækning og parsing
Når den er tilgængelig, udtrækker AI tekst og struktur.
For PDF-filer omfatter dette:
- Læser valgbar tekst
- Identifikation af siderækkefølge
- Genkender overskrifter
- Adskillelse af lister og tabeller
Billed-pdf'er reducerer udtrækningsnøjagtigheden.
Konvertering af billeder til PDF-filer hjælper med at analysere.
Fase 4: Strukturel fortolkning
AI fortolker derefter dokumentstrukturen.
Stærke signaler inkluderer:
- Klare titler
- Logiske overskrifter
- Konsekvent formatering
- Definerede sektioner
Dårlig struktur bremser forståelsen og reducerer tilliden.
Mange dokumenter forbedrer strukturen under redigering.
Eksempel på redigering af arbejdsgang:
- PDF til Word til forfining
- Word til PDF til endelig struktur
Trin 5: Semantisk forståelse
Efter struktur er genkendt, analyserer AI betydning.
Dette omfatter:
- Identifikation af hovedemner
- Forstå sammenhænge mellem sektioner
- Detektering af definitioner og forklaringer
- Kortlægning af enheder og begreber
Semantisk klarhed er vigtigere end gentagelse af søgeord.
Fase 6: Emneklassificering og klyngedannelse
AI tildeler dokumentet til emnekategorier.
Den sammenligner indhold med eksisterende dokumenter for at bestemme:
- Emnets relevans
- Lighed med kendte kilder
- Placering i emneklynger
Dokumenter, der stemmer tydeligt overens med en emneklynge, får større synlighed.
Udgivelse af relaterede dokumenter styrker konsekvent klassificeringen.
Trin 7: Opsummering og videnudvinding
AI genererer interne resuméer for at teste forståelsen.
Dokumenter af høj kvalitet:
- Opsummer klart
- Bevar nøglepunkter
- Oprethold logisk flow
Dårligt opsummeringssignal svag struktur eller uklare beskeder.
Rene opsummeringer forbedrer tilliden.
Fase 8: Kvalitets- og tillidsevaluering
AI evaluerer tillid og pålidelighed ved hjælp af indirekte signaler.
Disse omfatter:
- Konsistens på tværs af sektioner
- Saglig tone
- Fravær af manipulation
- Teknisk kvalitet
Signaler af lav kvalitet bremser eller stopper fremskridt i livscyklussen.
Fase 9: Kontekstuelle koblinger og relationer
AI evaluerer, hvordan dokumentet relaterer sig til andre.
Relaterede dokumenter, der:
- Del terminologi
- Dæk forbundne underemner
- Oprethold ensartet struktur
er knyttet sammen.
Sammenfletning af relaterede filer styrker konteksten.
Ensartet kontekst forbedrer forståelsen.
Trin 10: Indeksering og lagring
Når det er evalueret, indekseres dokumentet.
Indeksering omfatter:
- Lagring af semantisk repræsentation
- Tilknyttede enheder og emner
- Link til relateret indhold
Indekserede dokumenter bliver kvalificerede til søgeresultater og AI-oversigter.
Fase 11: Rangering og hentning
Når en bruger søger, henter AI dokumenter baseret på:
- Relevans
- Myndighed
- Klarhed
- Kontekstmatch
Ranking er dynamisk og påvirket af igangværende signaler.
Fase 12: Inkludering i AI-oversigter
Kun en delmængde af dokumenter påvirker AI-oversigter.
Dokumenter valgt typisk:
- Forklar emner klart
- Brug et neutralt sprog
- Undgå overdreven forfremmelse
- Giv fuldstændige svar
PDF-filer, der opfylder disse kriterier, er stærke kandidater.
Fælles brudpunkter i livscyklussen
Dokumenter fejler ofte ved:
- Tekstudtrækning på grund af indhold, der kun er billede
- Strukturel forvirring
- Manglende emnefokus
- Tekniske præstationsproblemer
Løsning af problemer i de tidlige stadier forbedrer nedstrøms synlighed.
Hvorfor standardisering forbedrer hele livscyklussen
Standardiserede PDF'er understøtter alle trin.
Fordelene omfatter:
- Lettere parsing
- Renere struktur
- Stabil semantik
- Bedre resuméer
Konvertering af proprietære formater såsom Pages forbedrer konsistensen.
Ekstern indsigt i indekseringssystemer
Ifølge Google Search Central , klar struktur og tilgængelighed hjælper systemerne med at forstå og indeksere indhold nøjagtigt:
Denne vejledning gælder også for PDF-filer.
Konklusion: Synlighed er en proces, ikke et øjeblik
AI-dokumentsynlighed er resultatet af en flertrins livscyklus. Fra opdagelse til opsummering afhænger hvert trin af klarhed, struktur og konsistens.
PDF-filer, der er standardiserede, optimerede og fokuserede, bevæger sig jævnt gennem denne livscyklus og får stærkere langsigtet synlighed. Forståelse af denne proces hjælper udgivere med at skabe dokumenter, der ikke kun udgives, men forstås. I AI-drevne søgemiljøer kommer succes fra at understøtte alle faser af indekseringens livscyklus.
Ofte stillede spørgsmål
Hvor lang tid tager AI-indeksering
Det varierer baseret på tilgængelighed, struktur og kvalitet.
Gennemgår PDF'er den samme livscyklus som websider
Ja. Principperne er de samme.
Kan dokumenter genindekseres
Ja. Opdateringer udløser reevaluering.
Påvirker filformat indeksering
Ja. Standardiserede formater indekserer mere pålideligt.
Kan dårlig struktur blokere indeksering
Ja. Strukturel forvirring kan stoppe udviklingen tidligt.