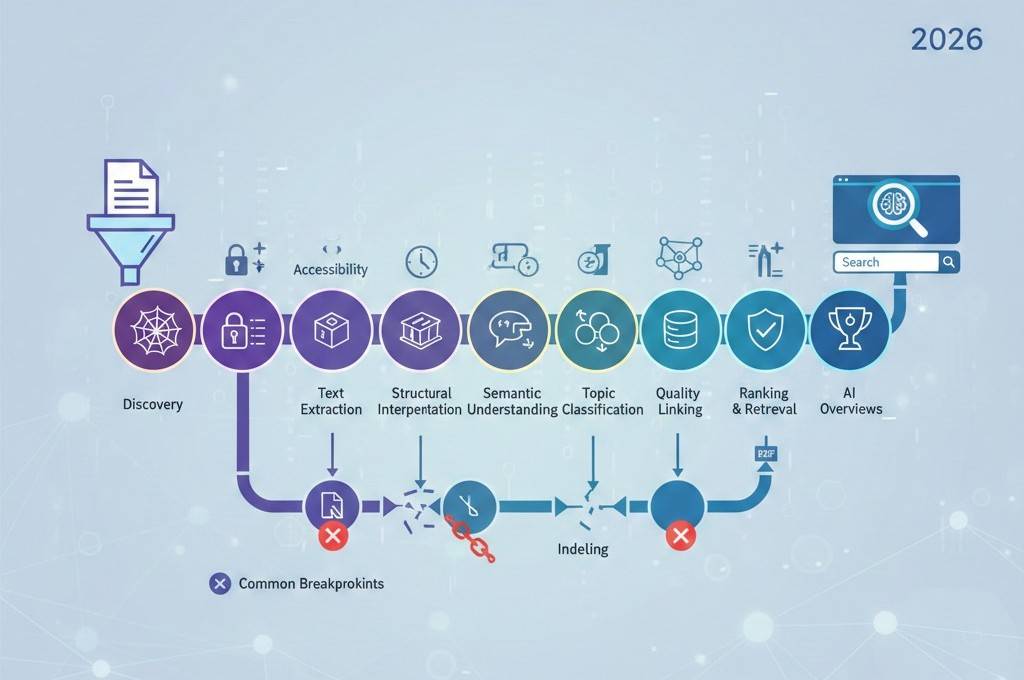
วงจรการจัดทำดัชนีเอกสาร AI อธิบายตั้งแต่การอัปโหลดไปจนถึงการมองเห็นการค้นหา
จะเกิดอะไรขึ้นหลังจากการเผยแพร่เอกสาร
การเผยแพร่เอกสารไม่ได้ทำให้มองเห็นได้โดยอัตโนมัติในการค้นหาที่ขับเคลื่อนโดย AI ในปี 2026 เอกสารจะเคลื่อนผ่านวงจรชีวิตที่มีโครงสร้างก่อนที่จะจัดทำดัชนี ทำความเข้าใจ สรุป และแสดงในผลการค้นหา
วงจรการใช้งานนี้ใช้กับหน้าเว็บและ PDF เหมือนกัน การทำความเข้าใจวิธีที่ระบบ AI ประมวลผลเอกสารช่วยให้ผู้จัดพิมพ์ปรับปรุงความชัดเจน การเข้าถึง และการมองเห็นในระยะยาว
บทความนี้จะอธิบายแต่ละขั้นตอนของวงจรการจัดทำดัชนีเอกสาร AI และคุณภาพของเอกสารส่งผลต่อผลลัพธ์ในทุกขั้นตอนอย่างไร
ขั้นตอนที่ 1: การค้นพบเอกสาร
วงจรชีวิตเริ่มต้นเมื่อระบบ AI ค้นพบเอกสาร
การค้นพบเกิดขึ้นผ่าน:
- การรวบรวมข้อมูล URL สาธารณะ
- การเชื่อมโยงภายใน
- การอ้างอิงภายนอก
- รูปแบบการเข้าถึงของผู้ใช้
เอกสารที่เข้าถึงได้ง่ายและเชื่อมโยงอย่างเหมาะสมจะถูกค้นพบเร็วขึ้น
การเผยแพร่ PDF ที่ได้มาตรฐานจะปรับปรุงการเข้าถึงข้ามแพลตฟอร์ม
ขั้นตอนที่ 2: การเข้าถึงไฟล์และความพร้อมทางเทคนิค
ก่อนที่ AI จะสามารถอ่านเนื้อหาได้ AI จะตรวจสอบการเข้าถึงทางเทคนิคก่อน
ปัจจัยสำคัญ ได้แก่ :
- ความพร้อมใช้งานของไฟล์
- โหลดประสิทธิภาพ
- ความเข้ากันได้ของรูปแบบ
- การแสดงผลที่ปราศจากข้อผิดพลาด
แนะนำให้ใช้ PDF เนื่องจากแสดงผลสม่ำเสมอ
การเพิ่มประสิทธิภาพขนาดไฟล์ ปรับปรุงการเข้าถึง
ไฟล์ขนาดเล็กช่วยลดแรงเสียดทานในการประมวลผล
ขั้นตอนที่ 3: การแยกข้อความและการแยกวิเคราะห์
เมื่อเข้าถึงได้ AI จะแยกข้อความและโครงสร้าง
สำหรับ PDF จะรวมถึง:
- การอ่านข้อความที่เลือกได้
- การระบุลำดับหน้า
- การรับรู้ส่วนหัว
- การแยกรายการและตาราง
PDF แบบรูปภาพเท่านั้นจะลดความแม่นยำในการแยกข้อมูล
การแปลงรูปภาพเป็น PDF ช่วยแยกวิเคราะห์
ขั้นตอนที่ 4: การตีความโครงสร้าง
AI จะตีความโครงสร้างเอกสาร
สัญญาณที่แข็งแกร่ง ได้แก่ :
- ล้างชื่อเรื่อง
- ส่วนหัวแบบลอจิคัล
- การจัดรูปแบบที่สอดคล้องกัน
- ส่วนที่กำหนดไว้
โครงสร้างที่ไม่ดีจะทำให้ความเข้าใจช้าลงและลดความมั่นใจ
เอกสารจำนวนมากปรับปรุงโครงสร้างระหว่างการแก้ไข
การแก้ไขตัวอย่างขั้นตอนการทำงาน:
- PDF เป็น Word เพื่อความประณีต
- คำเป็น PDF สำหรับโครงสร้างขั้นสุดท้าย
ขั้นที่ 5: ความเข้าใจเชิงความหมาย
หลังจากรับรู้โครงสร้างแล้ว AI จะวิเคราะห์ความหมาย
ซึ่งรวมถึง:
- การระบุหัวข้อหลัก
- ทำความเข้าใจความสัมพันธ์ระหว่างส่วนต่างๆ
- การตรวจจับคำจำกัดความและคำอธิบาย
- การทำแผนที่เอนทิตีและแนวคิด
ความชัดเจนของความหมายมีความสำคัญมากกว่าการกล่าวซ้ำคำหลัก
ขั้นตอนที่ 6: การจำแนกหัวข้อและการจัดกลุ่ม
AI กำหนดเอกสารตามหมวดหมู่หัวข้อ
โดยจะเปรียบเทียบเนื้อหากับเอกสารที่มีอยู่เพื่อกำหนด:
- ความเกี่ยวข้องของหัวข้อ
- ความคล้ายคลึงกับแหล่งที่รู้จัก
- ตำแหน่งภายในกลุ่มหัวข้อ
เอกสารที่สอดคล้องกับกลุ่มหัวข้ออย่างชัดเจนจะทำให้มองเห็นได้ชัดเจนยิ่งขึ้น
การเผยแพร่เอกสารที่เกี่ยวข้องช่วยเสริมสร้างการจำแนกประเภทอย่างต่อเนื่อง
ขั้นตอนที่ 7: การสรุปและการดึงความรู้
AI สร้างบทสรุปภายในเพื่อทดสอบความเข้าใจ
เอกสารคุณภาพสูง:
- สรุปให้ชัดเจน
- อนุรักษ์ประเด็นสำคัญไว้
- รักษากระแสตรรกะ
สัญญาณสรุปที่ไม่ดี โครงสร้างที่อ่อนแอหรือข้อความที่ไม่ชัดเจน
บทสรุปที่ชัดเจนช่วยเพิ่มความมั่นใจ
ขั้นตอนที่ 8: การประเมินคุณภาพและความน่าเชื่อถือ
AI ประเมินความน่าเชื่อถือและความน่าเชื่อถือโดยใช้สัญญาณทางอ้อม
ซึ่งรวมถึง:
- ความสม่ำเสมอทั่วทั้งส่วน
- เสียงจริง
- ขาดการจัดการ
- คุณภาพทางเทคนิค
สัญญาณคุณภาพต่ำจะชะลอหรือหยุดความคืบหน้าในวงจรชีวิต
ขั้นตอนที่ 9: การเชื่อมโยงตามบริบทและความสัมพันธ์
AI จะประเมินว่าเอกสารเกี่ยวข้องกับผู้อื่นอย่างไร
เอกสารที่เกี่ยวข้องที่:
- แบ่งปันคำศัพท์
- ครอบคลุมหัวข้อย่อยที่เชื่อมโยง
- รักษาโครงสร้างให้สม่ำเสมอ
มีการเชื่อมโยงเข้าด้วยกัน
การรวมไฟล์ที่เกี่ยวข้อง เสริมสร้างบริบท
บริบทที่เป็นหนึ่งเดียวช่วยเพิ่มความเข้าใจ
ขั้นตอนที่ 10: การจัดทำดัชนีและการจัดเก็บ
เมื่อประเมินแล้ว เอกสารจะถูกจัดทำดัชนี
การจัดทำดัชนีประกอบด้วย:
- การจัดเก็บการแสดงความหมาย
- การเชื่อมโยงเอนทิตีและหัวข้อ
- การเชื่อมโยงกับเนื้อหาที่เกี่ยวข้อง
เอกสารที่จัดทำดัชนีจะมีสิทธิ์สำหรับผลการค้นหาและข้อมูลสรุป AI
ด่าน 11: การจัดอันดับและการดึงข้อมูล
เมื่อผู้ใช้ค้นหา AI จะดึงเอกสารตาม:
- ความเกี่ยวข้อง
- อำนาจ
- ความชัดเจน
- การจับคู่บริบท
การจัดอันดับเป็นแบบไดนามิกและได้รับอิทธิพลจากสัญญาณที่กำลังดำเนินอยู่
ขั้นตอนที่ 12: การรวมอยู่ในภาพรวม AI
มีเพียงเอกสารบางส่วนเท่านั้นที่มีอิทธิพลต่อภาพรวม AI
โดยทั่วไปเอกสารที่เลือก:
- อธิบายหัวข้อให้ชัดเจน
- ใช้ภาษาที่เป็นกลาง
- หลีกเลี่ยงการส่งเสริมมากเกินไป
- ให้คำตอบที่สมบูรณ์
PDF ที่ตรงตามเกณฑ์เหล่านี้ถือเป็นผู้สมัครที่แข็งแกร่ง
จุดพักทั่วไปในวงจรชีวิต
เอกสารมักจะล้มเหลวที่:
- การแยกข้อความเนื่องจากเนื้อหารูปภาพเท่านั้น
- ความสับสนทางโครงสร้าง
- ขาดการมุ่งเน้นหัวข้อ
- ปัญหาประสิทธิภาพทางเทคนิค
การแก้ไขปัญหาในระยะเริ่มแรกช่วยเพิ่มทัศนวิสัยปลายน้ำ
เหตุใดการกำหนดมาตรฐานจึงปรับปรุงวงจรชีวิตทั้งหมด
PDF ที่ได้มาตรฐานรองรับทุกขั้นตอน
สิทธิประโยชน์ ได้แก่:
- แยกวิเคราะห์ได้ง่ายขึ้น
- โครงสร้างที่สะอาดยิ่งขึ้น
- ความหมายที่มั่นคง
- สรุปดีกว่า.
การแปลงรูปแบบที่เป็นกรรมสิทธิ์ เช่น Pages จะปรับปรุงความสอดคล้องกัน
ข้อมูลเชิงลึกภายนอกเกี่ยวกับระบบการจัดทำดัชนี
ตาม ศูนย์กลางการค้นหาของ Google โครงสร้างที่ชัดเจนและการเข้าถึงช่วยให้ระบบเข้าใจและจัดทำดัชนีเนื้อหาได้อย่างถูกต้อง:
คำแนะนำนี้ใช้ได้กับ PDF อย่างเท่าเทียมกัน
บทสรุป: การมองเห็นเป็นกระบวนการ ไม่ใช่ชั่วขณะหนึ่ง
การมองเห็นเอกสาร AI เป็นผลมาจากวงจรชีวิตแบบหลายขั้นตอน ตั้งแต่การค้นพบไปจนถึงการสรุป แต่ละขั้นตอนขึ้นอยู่กับความชัดเจน โครงสร้าง และความสม่ำเสมอ
PDF ที่ได้รับมาตรฐาน ปรับให้เหมาะสม และเน้นไปที่การเคลื่อนไหวอย่างราบรื่นตลอดวงจรชีวิตนี้ และมองเห็นได้ชัดเจนยิ่งขึ้นในระยะยาว การทำความเข้าใจกระบวนการนี้ช่วยให้ผู้จัดพิมพ์สร้างเอกสารที่ไม่เพียงแต่เผยแพร่เท่านั้น แต่ยังเป็นที่เข้าใจอีกด้วย ในสภาพแวดล้อมการค้นหาที่ขับเคลื่อนด้วย AI ความสำเร็จมาจากการสนับสนุนทุกขั้นตอนของวงจรการจัดทำดัชนี
คำถามที่พบบ่อย
การจัดทำดัชนี AI ใช้เวลานานเท่าใด
ซึ่งจะแตกต่างกันไปตามการเข้าถึง โครงสร้าง และคุณภาพ
PDF มีวงจรชีวิตเดียวกันกับหน้าเว็บหรือไม่
ใช่. หลักการก็เหมือนกัน
สามารถจัดทำดัชนีเอกสารใหม่ได้
ใช่. การอัปเดตทำให้เกิดการประเมินใหม่
รูปแบบไฟล์ส่งผลต่อการจัดทำดัชนีหรือไม่
ใช่. ดัชนีรูปแบบมาตรฐานมีความน่าเชื่อถือมากขึ้น
การจัดทำดัชนีบล็อกโครงสร้างที่ไม่ดีสามารถ
ใช่. ความสับสนทางโครงสร้างสามารถหยุดความคืบหน้าได้ตั้งแต่เนิ่นๆ