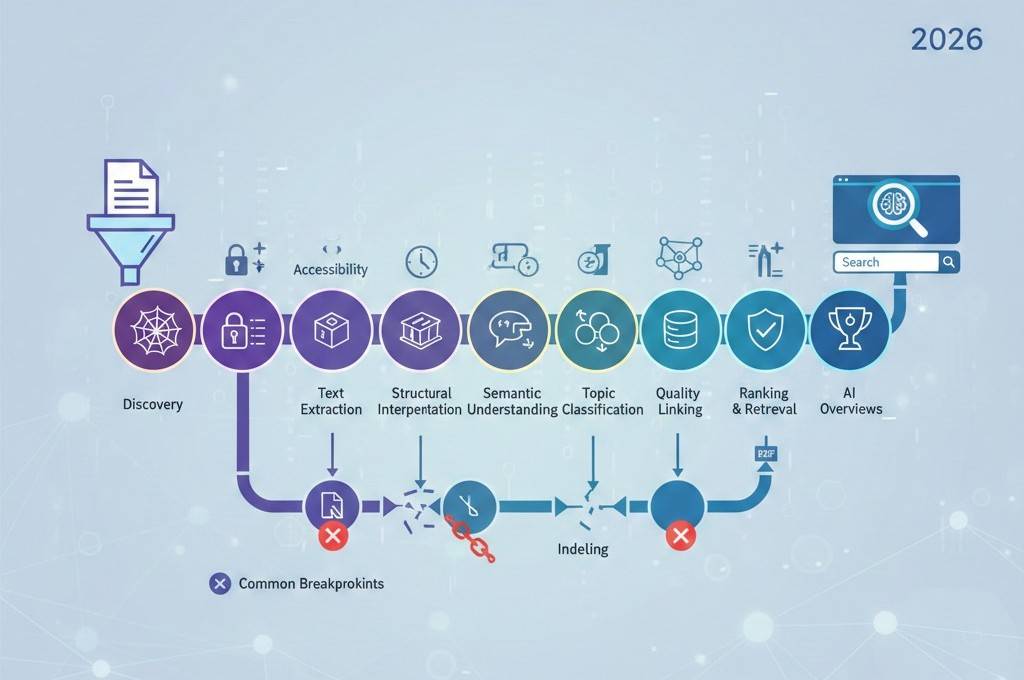
De levenscyclus van AI-documentindexering uitgelegd, van upload tot zoekzichtbaarheid
Wat er gebeurt nadat een document is gepubliceerd
Het publiceren van een document maakt het niet automatisch zichtbaar in AI-gestuurde zoekopdrachten. In 2026 doorlopen documenten een gestructureerde levenscyclus voordat ze kunnen worden geïndexeerd, begrepen, samengevat en in zoekresultaten kunnen worden weergegeven.
Deze levenscyclus geldt zowel voor webpagina's als voor PDF's. Door te begrijpen hoe AI-systemen documenten verwerken, kunnen uitgevers de duidelijkheid, toegankelijkheid en zichtbaarheid op de lange termijn verbeteren.
In dit artikel wordt elke fase van de levenscyclus van AI-documentindexering uitgelegd en hoe de documentkwaliteit de resultaten bij elke stap beïnvloedt.
Fase 1: Documentdetectie
De levenscyclus begint wanneer AI-systemen een document ontdekken.
Ontdekking vindt plaats door:
- Openbare URL's crawlen
- Interne koppeling
- Externe referenties
- Patronen voor gebruikerstoegang
Documenten die gemakkelijk toegankelijk zijn en goed gekoppeld zijn, worden sneller ontdekt.
Het publiceren van gestandaardiseerde PDF's verbetert de toegankelijkheid op verschillende platforms.
Fase 2: Bestandstoegankelijkheid en technische gereedheid
Voordat AI inhoud kan lezen, controleert het de technische toegankelijkheid.
Belangrijke factoren zijn onder meer:
- Beschikbaarheid van bestanden
- Prestaties laden
- Formaatcompatibiliteit
- Foutloze weergave
PDF's hebben de voorkeur omdat ze consistent worden weergegeven.
Bestandsgrootte optimaliseren verbetert de toegankelijkheid.
Kleinere bestanden verminderen verwerkingsfrictie.
Fase 3: Tekstextractie en parseren
Eenmaal toegankelijk, extraheert AI tekst en structuur.
Voor PDF's omvat dit:
- Selecteerbare tekst lezen
- Paginavolgorde identificeren
- Herkennen van kopjes
- Lijsten en tabellen scheiden
PDF's met alleen afbeeldingen verminderen de nauwkeurigheid van de extractie.
Afbeeldingen converteren naar PDF's helpt bij het ontleden.
Fase 4: Structurele interpretatie
AI interpreteert vervolgens de documentstructuur.
Sterke signalen zijn onder meer:
- Duidelijke titels
- Logische kopjes
- Consistente opmaak
- Gedefinieerde secties
Een slechte structuur vertraagt het begrip en vermindert het vertrouwen.
Veel documenten verbeteren de structuur tijdens het bewerken.
Voorbeeld van een workflow bewerken:
- PDF naar Word voor verfijning
- Word naar PDF voor de uiteindelijke structuur
Fase 5: Semantisch begrip
Nadat de structuur is herkend, analyseert AI de betekenis.
Dit omvat:
- Het identificeren van hoofdonderwerpen
- Relaties tussen secties begrijpen
- Het detecteren van definities en verklaringen
- In kaart brengen van entiteiten en concepten
Semantische duidelijkheid is belangrijker dan herhaling van trefwoorden.
Fase 6: Onderwerpclassificatie en clustering
AI wijst het document toe aan onderwerpcategorieën.
Het vergelijkt de inhoud met bestaande documenten om het volgende te bepalen:
- Relevantie van het onderwerp
- Gelijkenis met bekende bronnen
- Plaatsing binnen onderwerpclusters
Documenten die duidelijk aansluiten bij een onderwerpcluster krijgen een betere zichtbaarheid.
Het publiceren van gerelateerde documenten versterkt de classificatie consequent.
Fase 7: Samenvatten en kennisextractie
AI genereert interne samenvattingen om het begrip te testen.
Documenten van hoge kwaliteit:
- Vat het duidelijk samen
- Bewaar belangrijke punten
- Zorg voor een logische stroom
Slechte samenvattingen geven een signaal zwakke structuur of onduidelijke berichtgeving.
Schone samenvattingen vergroten het vertrouwen.
Fase 8: Evaluatie van kwaliteit en vertrouwen
AI evalueert vertrouwen en betrouwbaarheid met behulp van indirecte signalen.
Deze omvatten:
- Consistentie tussen secties
- Feitelijke toon
- Afwezigheid van manipulatie
- Technische kwaliteit
Signalen van lage kwaliteit vertragen of stoppen de voortgang in de levenscyclus.
Fase 9: Contextuele koppelingen en relaties
AI evalueert hoe het document zich verhoudt tot anderen.
Gerelateerde documenten die:
- Deel terminologie
- Behandel verbonden subonderwerpen
- Zorg voor een consistente structuur
zijn met elkaar verbonden.
Gerelateerde bestanden samenvoegen versterkt de context.
Uniforme context verbetert het begrip.
Fase 10: Indexering en opslag
Na evaluatie wordt het document geïndexeerd.
Indexering omvat:
- Semantische representatie opslaan
- Entiteiten en onderwerpen koppelen
- Koppeling met gerelateerde inhoud
Geïndexeerde documenten komen in aanmerking voor zoekresultaten en AI-samenvattingen.
Fase 11: Rangschikking en terugwinning
Wanneer een gebruiker zoekt, haalt AI documenten op op basis van:
- Relevantie
- Autoriteit
- Helderheid
- Contextovereenkomst
De ranking is dynamisch en wordt beïnvloed door voortdurende signalen.
Fase 12: Opname in AI-overzichten
Slechts een subset van documenten heeft invloed op AI-overzichten.
Documenten die doorgaans worden geselecteerd:
- Leg onderwerpen duidelijk uit
- Gebruik neutrale taal
- Vermijd buitensporige promotie
- Geef volledige antwoorden
PDF's die aan deze criteria voldoen, zijn sterke kandidaten.
Gemeenschappelijke breekpunten in de levenscyclus
Documenten mislukken vaak bij:
- Tekstextractie vanwege inhoud met alleen afbeeldingen
- Structurele verwarring
- Gebrek aan onderwerpfocus
- Technische prestatieproblemen
Door problemen in een vroeg stadium op te lossen, wordt de zichtbaarheid stroomafwaarts verbeterd.
Waarom standaardisatie de hele levenscyclus verbetert
Gestandaardiseerde PDF's ondersteunen elke fase.
Voordelen zijn onder meer:
- Gemakkelijker parseren
- Schonere structuur
- Stabiele semantiek
- Betere samenvattingen
Het converteren van bedrijfseigen formaten zoals Pages verbetert de consistentie.
Extern inzicht in indexeringssystemen
Volgens Google Zoeken Centraal Dankzij de duidelijke structuur en toegankelijkheid kunnen systemen de inhoud nauwkeurig begrijpen en indexeren:
Deze richtlijnen zijn eveneens van toepassing op PDF's.
Conclusie: Zichtbaarheid is een proces, geen moment
De zichtbaarheid van AI-documenten is het resultaat van een levenscyclus in meerdere fasen. Van ontdekking tot samenvatting: elke stap is afhankelijk van duidelijkheid, structuur en consistentie.
PDF's die gestandaardiseerd, geoptimaliseerd en gericht zijn, doorlopen deze levenscyclus soepel en krijgen een sterkere zichtbaarheid op de lange termijn. Door dit proces te begrijpen, kunnen uitgevers documenten creëren die niet alleen worden gepubliceerd, maar ook worden begrepen. In AI-gestuurde zoekomgevingen komt succes voort uit het ondersteunen van elke fase van de indexeringslevenscyclus.
Veelgestelde vragen
Hoe lang duurt AI-indexering
Het varieert op basis van toegankelijkheid, structuur en kwaliteit.
Gaan PDF's dezelfde levenscyclus door als webpagina's?
Ja. De principes zijn hetzelfde.
Kunnen documenten opnieuw worden geïndexeerd?
Ja. Updates leiden tot herevaluatie.
Heeft het bestandsformaat invloed op de indexering?
Ja. Gestandaardiseerde formaten indexeren betrouwbaarder.
Kan een slechte structuur de indexering blokkeren
Ja. Structurele verwarring kan de vooruitgang voortijdig tegenhouden.