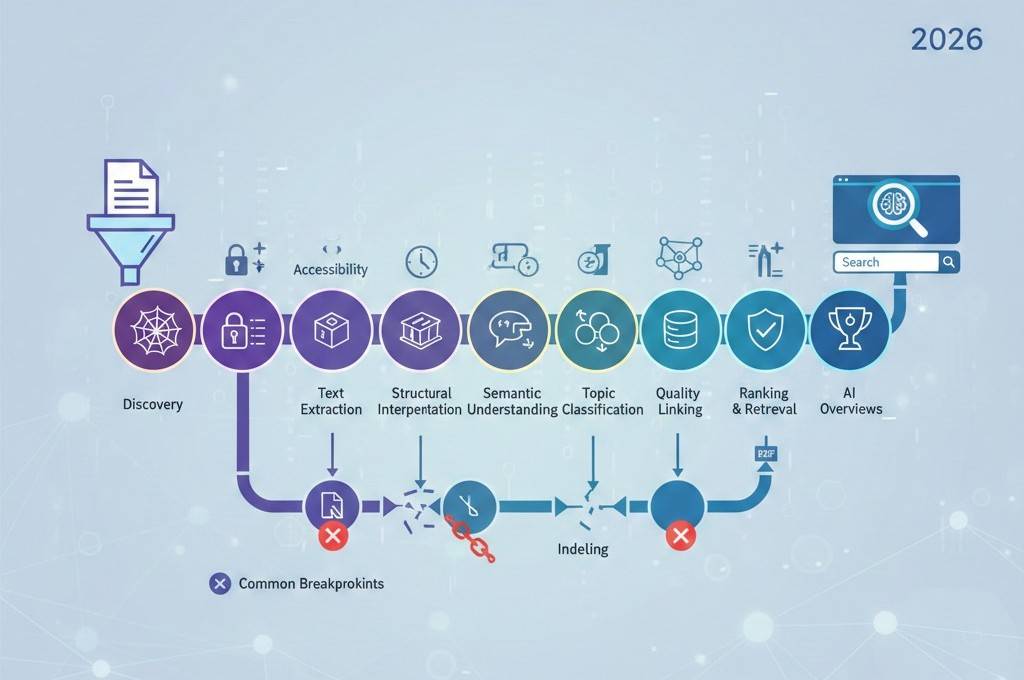
アップロードから検索可視化までの AI ドキュメント インデックス作成ライフサイクルの説明
ドキュメントの公開後に何が起こるか
ドキュメントを公開しても、AI を利用した検索で自動的に表示されるわけではありません。 2026 年、ドキュメントは構造化されたライフサイクルを経て、インデックス付けされ、理解され、要約され、検索結果に表示されます。
このライフサイクルは、Web ページと PDF の両方に適用されます。 AI システムがドキュメントを処理する方法を理解することは、出版社が明瞭さ、アクセシビリティ、長期的な可視性を向上させるのに役立ちます。
この記事では、AI ドキュメントのインデックス作成ライフサイクルの各段階と、ドキュメントの品質が各ステップの結果にどのように影響するかについて説明します。
ステージ 1: 文書の発見
ライフサイクルは、AI システムがドキュメントを検出したときに始まります。
検出は次の方法で行われます。
- パブリック URL のクロール
- 内部リンク
- 外部参照
- ユーザーのアクセスパターン
アクセスしやすく、適切にリンクされているドキュメントは、より早く発見されます。
標準化された PDF を公開すると、プラットフォーム間でのアクセシビリティが向上します。
ステージ 2: ファイルのアクセシビリティと技術的な準備
AI はコンテンツを読み取る前に、技術的なアクセシビリティをチェックします。
主な要素には次のようなものがあります。
- ファイルの利用可能性
- 負荷パフォーマンス
- フォーマットの互換性
- エラーのないレンダリング
PDF は一貫してレンダリングされるため、推奨されます。
ファイルサイズの最適化 アクセシビリティを向上させます。
ファイルが小さいほど、処理の負荷が軽減されます。
ステージ 3: テキストの抽出と解析
アクセスできると、AI がテキストと構造を抽出します。
PDF の場合、これには以下が含まれます。
- 選択可能なテキストの読み取り
- ページ順序の識別
- 見出しの認識
- リストとテーブルの分離
画像のみの PDF では抽出精度が低下します。
画像を PDF に変換する 解析に役立ちます。
ステージ 4: 構造の解釈
AI が文書構造を解釈します。
強いシグナルには次のようなものがあります。
- タイトルをクリアする
- 論理見出し
- 一貫した書式設定
- 定義されたセクション
構造が不十分だと理解が遅れ、自信が失われます。
多くのドキュメントでは、編集中に構造が改善されます。
編集ワークフローの例:
- PDFからWordへ 洗練のために
- WordからPDFへ 最終構造用
ステージ 5: 意味の理解
構造を認識した後、AIが意味を解析します。
これには以下が含まれます。
- 主要なトピックの特定
- セクション間の関係を理解する
- 定義と説明の検出
- エンティティと概念のマッピング
意味の明確さは、キーワードの繰り返しよりも重要です。
ステージ 6: トピックの分類とクラスタリング
AI はドキュメントをトピック カテゴリに割り当てます。
コンテンツを既存のドキュメントと比較して、次のことを判断します。
- トピックの関連性
- 既知の情報源との類似性
- トピッククラスター内の配置
トピック クラスタと明確に一致するドキュメントは、より強力な可視性を獲得します。
関連文書を公開すると、分類が一貫して強化されます。
ステージ 7: 要約と知識の抽出
AI は理解度をテストするための内部要約を生成します。
高品質のドキュメント:
- わかりやすく要約する
- 重要なポイントを守る
- 論理的な流れを維持する
サマリーシグナルが不十分 構造が弱いか、メッセージが不明確です。
簡潔な要約は自信を高めます。
ステージ 8: 品質と信頼性の評価
AIは間接的なシグナルを使用して信頼性と信頼性を評価します。
これらには次のものが含まれます。
- セクション間の一貫性
- 事実に基づく論調
- 操作の不在
- 技術的品質
信号の品質が低いと、ライフサイクルの進行が遅くなったり、止まったりします。
ステージ 9: コンテキストに基づくリンクと関係
AI は文書が他の文書とどのように関連しているかを評価します。
以下の関連文書:
- 用語の共有
- つながりのあるサブトピックをカバーする
- 一貫した構造を維持する
相互にリンクされています。
関連ファイルのマージ 文脈を強化します。
統一されたコンテキストにより理解が向上します。
ステージ 10: インデックス作成とストレージ
評価が完了すると、ドキュメントにインデックスが付けられます。
インデックスには次のものが含まれます。
- 意味表現の保存
- エンティティとトピックの関連付け
- 関連コンテンツとのリンク
インデックス付きドキュメントは、検索結果および AI 概要の対象となります。
ステージ 11: ランキングと取得
ユーザーが検索すると、AI は以下に基づいてドキュメントを取得します。
- 関連性
- 権限
- 明瞭さ
- コンテキストの一致
ランキングは動的であり、進行中のシグナルの影響を受けます。
ステージ 12: AI の概要への組み込み
AI の概要に影響を与えるのはドキュメントのサブセットのみです。
通常、選択されるドキュメントは次のとおりです。
- トピックをわかりやすく説明する
- 中立的な言語を使用する
- 過度な宣伝は避ける
- 完全な回答を提供する
これらの基準を満たす PDF が有力な候補です。
ライフサイクルにおける一般的なブレークポイント
ドキュメントは次の点で失敗することがよくあります。
- 画像のみのコンテンツによるテキスト抽出
- 構造的な混乱
- トピックの焦点の欠如
- 技術的なパフォーマンスの問題
初期段階の問題を修正すると、下流の可視性が向上します。
標準化によってライフサイクル全体が改善される理由
標準化された PDF はあらゆる段階をサポートします。
利点は次のとおりです。
- より簡単な解析
- よりクリーンな構造
- 安定したセマンティクス
- より良い要約
Pages などの独自形式を変換すると、一貫性が向上します。
インデックス作成システムに関する外部の洞察
によると Google 検索セントラル 、明確な構造とアクセシビリティにより、システムはコンテンツを正確に理解し、インデックスを付けることができます。
このガイダンスは PDF にも同様に適用されます。
結論: 可視化は瞬間ではなくプロセスである
AI ドキュメントの可視性は、複数段階のライフサイクルの結果です。発見から要約までの各ステップは、明確さ、構造、一貫性によって決まります。
標準化され、最適化され、焦点が絞られた PDF は、このライフサイクルをスムーズに通過し、長期的な可視性が強化されます。このプロセスを理解することは、発行者が発行されるだけでなく理解される文書を作成するのに役立ちます。 AI 主導の検索環境では、インデックス作成ライフサイクルのあらゆる段階をサポートすることが成功の鍵となります。
よくある質問
AI インデックス作成にはどのくらい時間がかかりますか
アクセシビリティ、構造、品質によって異なります。
PDF は Web ページと同じライフサイクルを経ますか
はい。原則は同じです。
ドキュメントのインデックスを再作成できますか
はい。更新により再評価が行われます。
ファイル形式はインデックス作成に影響しますか
はい。標準化された形式により、インデックスの信頼性が高まります。
構造ブロックのインデックス付けが不十分である可能性がある
はい。構造的な混乱により、進歩が早期に停止する可能性があります。